
「ClaudeにPDFを読み込ませても、肝心な部分を飛ばされてしまう」「社内ルールに沿った回答をしてほしいのに、一般的なことしか言ってくれない」そんな風に悩んでいませんか。Claudeの賢さを引き出すには、RAGという仕組みを正しく組み込むのが一番の近道です。
この記事では、あなたの持っている独自のデータをClaudeと連携させて、仕事の相棒として完璧に動かすための手順を分かりやすくお伝えします。専門用語も噛み砕いて説明するので、まずは全体の流れを掴んでみてください。読み終える頃には、精度の高いAIアシスタントを作る具体的なイメージが湧いているはずです。
Claude RAGの仕組みと基本の動き
RAGとは、簡単に言うと「AIに持ち込み不可の試験を受けさせるのではなく、横に参考書を置いて調べながら答えさせる」仕組みのことです。AIが学習していない最新のニュースや、あなただけが持っているメモをその場で読み取って回答に活かしてくれます。
この方法を使えば、AIが適当な嘘をつく「ハルシネーション」をぐっと減らせます。Claudeは特に、渡された資料を読み解く力が他のAIよりも優れているため、RAGとの相性が抜群に良いのです。
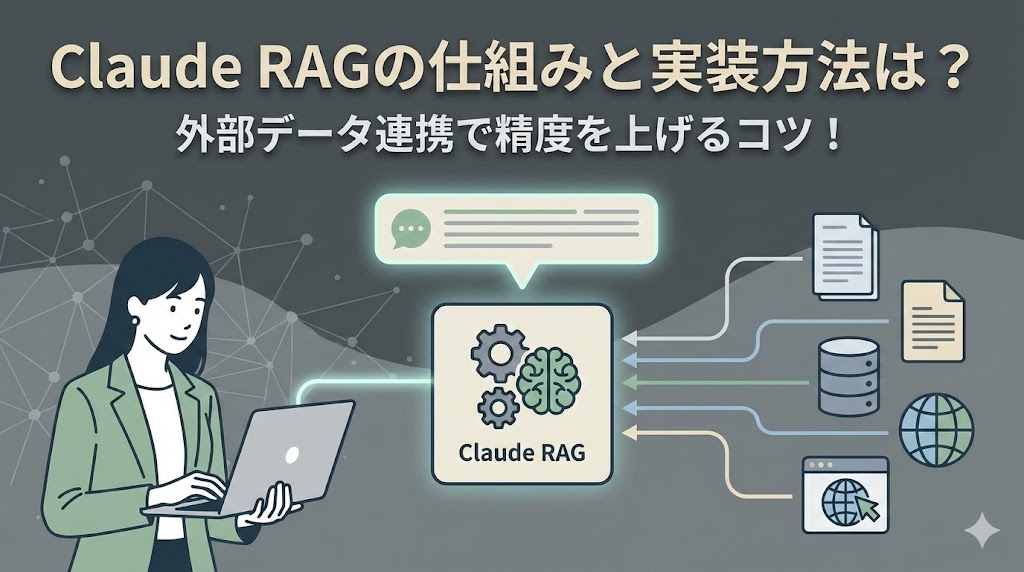
外部ドキュメントを検索して回答を作る流れ
RAGの動きは、大きく分けて「検索」と「生成」の2段階に分かれています。まずユーザーが質問をすると、システムが大量のPDFやテキストデータの中から、その質問に関係がありそうな部分だけをピックアップします。
次に、選ばれた情報の断片をClaudeに渡し、「この資料を読んで質問に答えて」と命令を出します。これにより、Claudeは自分の記憶に頼ることなく、目の前の確かな情報だけを使って正確な回答を作れるようになります。
なぜClaudeは大量のデータ読み込みに強いのか
Claude 3.5 Sonnetなどのモデルは、一度に処理できる情報の量を示す「コンテキストウィンドウ」が20万トークンと非常に大きいです。これは、日本語の文庫本でいえば2冊分近い内容を丸ごと一度に読み込める計算になります。
他のAIだと、資料が長すぎると最初の方を忘れてしまうことがありますが、Claudeなら心配ありません。たくさんの資料を一度に渡しても、細かい文脈までしっかり把握して矛盾のない答えを返してくれます。
嘘をつかない回答を実現する仕組み
RAGを使う最大のメリットは、回答の根拠がはっきりすることです。Claudeは指示に対して忠実なので、「資料に書いていないことは『分からない』と答えて」と頼めば、勝手な想像で嘘をつくのをピタリと止められます。
また、回答の最後に「資料の3ページ目を参照しました」といった引用元を添えさせることも簡単です。これなら、人間が後から内容をダブルチェックするのも楽になり、安心して業務に導入できます。
クラウドを使ったClaude RAGの実装方法
自分で難しいプログラムを一から書かなくても、大手のクラウドサービスを使えばRAGの環境はすぐに整います。特にAWSやGoogleの環境は、ボタン操作だけでデータ連携ができる機能が充実しているのが魅力です。
ここでは、今すぐ始めたい方向けに、世界中の企業で使われている王道の構築パターンをいくつか見ていきましょう。
Amazon Bedrockでサーバーレスに構築する手順
AWSが提供する「Amazon Bedrock」の「Knowledge Bases」という機能を使うのが、最も手軽で強力な方法です。S3というストレージにPDFを放り込むだけで、あとはAWS側が自動で検索しやすい形にデータを加工してくれます。
難しい設定を抜きにして、Claudeの高度な推論能力をそのまま社内データに繋げられるのが強みです。
| 項目 | 内容 | 他との違い |
| サービス名 | Amazon Bedrock Knowledge Bases | サーバー管理が不要で楽 |
| 利用モデル | Claude 3.5 Sonnet / Claude 3 Haiku | 最新のClaudeがすぐ使える |
| データ源 | Amazon S3 | 大量のファイルを一括管理できる |
| 料金 | 従量課金(使った分だけ) | 初期費用なしでスモールスタート可 |
Google Vertex AIを活用した連携のやり方
Google Cloudを使っているなら、Vertex AI経由でClaudeを利用する手もあります。Googleの強力な検索技術をそのままRAGの「検索部分」に流用できるため、情報のヒット率が高くなるのが特徴です。
企業向けのセキュリティ基準も満たしているため、機密性の高いデータを扱う場合でも安心感があります。Googleドキュメントやスプレッドシートとの連携もスムーズに行えます。
APIとベクトルDBを自前で組み合わせる構成
より細かく動作をカスタマイズしたいなら、Anthropic社のAPIと「Pinecone」などのベクトルデータベースを直接繋ぐ方法がおすすめです。データの検索アルゴリズムを自分で調整できるため、究極の精度を追い求めることができます。
少しプログラミングの知識は必要ですが、特定の業界用語に特化させたい場合などは、この構成が一番自由度高く動かせます。
外部データ連携で精度を上げる事前準備
RAGの性能は、実はAIの賢さよりも「読み込ませるデータの質」で決まります。ぐちゃぐちゃな資料を渡されては、どんなに優秀なClaudeでも正しい答えは見つけられません。
まずは、AIが読みやすいようにデータを整える「お掃除」から始めてみましょう。
読み込ませるファイルの形式と整理のコツ
PDFファイルは見た目はきれいですが、中身のテキストがバラバラの順序で保存されていることがよくあります。できれば、プレーンなテキスト形式(.txt)やマークダウン形式(.md)に変換してから読み込ませるのが理想的です。
特に、改行の位置や文字化けを直しておくだけで、Claudeの理解スピードは劇的に上がります。
- 不要なヘッダーやフッターを削除する
- ページ番号などのノイズを取り除く
- 章立てをハッシュ記号(#)などで明確にする
表組みや図解をテキストで説明する方法
AIは画像の中にある図や、複雑な表を読み取るのがまだ少し苦手です。資料の中に重要なグラフがある場合は、その内容をあらかじめ文章で補足しておくと親切です。
「この表は、2025年度の売上目標を月別に示したものです」といった一文を添えるだけで、Claudeは迷わずその数値を引用できるようになります。
重複した情報や古いデータを排除する重要性
同じ内容の資料が何個もあると、AIはどれを信じていいか迷ってしまいます。情報の「鮮度」を保つために、古いマニュアルや下書きのファイルは思い切って削除するか、別フォルダに避けておきましょう。
常に「これさえ見れば正解がわかる」という最新の1ファイルだけを検索対象にするのが、ハルシネーションを防ぐ一番の薬です。
データの「切り分け」で検索の精度を上げる方法
RAGでは、長い文章をそのまま検索にかけるのではなく、数行ずつの「塊(チャンク)」に刻んで管理します。この刻み方が下手だと、必要な情報が途中でぶった切られてしまい、Claudeが文脈を読み取れなくなります。
1ブロックあたりの文字数はどれくらいがベスト?
一般的には、日本語で500文字から1000文字程度に区切るのがバランスが良いとされています。短すぎると意味が通じなくなり、長すぎると検索に関係ないノイズが増えてしまうからです。
まずは300トークン前後(日本語で約400文字)を目安に設定し、回答が不安定なら少しずつ大きく調整してみるのがおすすめです。
意味のつながりを壊さない分割のテクニック
機械的に文字数だけで区切ると、文章の途中でブチっと切れてしまいます。句読点や改行の位置で区切るように設定し、さらに「前後のブロックと少しだけ内容を重ねる」のがコツです。
重なりを作ることで、ブロックの端っこに書かれた重要な情報も漏らさず検索に引っかかるようになります。
Contextual Retrievalでデータの文脈を守る
Anthropic社が推奨している「Contextual Retrieval」という手法は、今のトレンドです。これは、分割した小さな塊のそれぞれに、「この記事は、〇〇プロジェクトの予算について書かれた部分です」という短い紹介文を自動で付け加える技術です。
これを行うだけで、切り分けられた断片的なデータでも、Claudeは「これが何についての話か」を即座に理解できるようになります。
回答の質をワンランク上げる最新の検索技術
ただのキーワード検索では、「スマホ」と調べたときに「スマートフォン」という言葉が含まれる資料を見落としてしまうことがあります。これを解決するのが、意味の近さで探す最新の技術です。
ベクトル検索とキーワード検索を混ぜるメリット
「ハイブリッド検索」と呼ばれる手法を取り入れましょう。言葉の響きが似ているものを探す「ベクトル検索」と、特定の単語がズバリ入っているものを探す「キーワード検索」のいいとこ取りです。
型番などの正確な一致が必要な情報と、ふわっとした概念の両方を漏らさずキャッチできるようになります。
日本語に強い埋め込みモデルの選び方
検索をスムーズにするには、文章を数値化する「埋め込みモデル」選びが重要です。Claudeとの相性が抜群なのは、Anthropicも推奨している「Voyage AI」です。
日本語の微妙なニュアンスも正確に数値に変えてくれるため、他のモデルを使うよりも「欲しい情報がちゃんと上位に出てくる」ようになります。
検索結果を並び替える「リランク」の威力
検索エンジンが持ってきた上位10個くらいの情報を、最後にもう一度AIに精査させるのが「リランク」です。「本当にこの質問の答えとして相応しいのはどれ?」と再判定させます。
ひと手間増えますが、これを入れるだけで回答の質がプロレベルに跳ね上がります。
Claudeの能力を引き出すプロンプトの書き方
準備したデータをClaudeに渡すとき、どんな風に「お願い」をするかで結果は変わります。Claudeは情報の整理整頓が大好きなので、タグを使って「ここは資料、ここは質問」と区別してあげましょう。
XMLタグを使って情報を整理して渡す技
Claudeは <docs> や <source> といったタグで囲まれた情報を理解するのが得意です。この書き方をすると、指示と資料を混同しなくなり、処理の精度が上がります。
Claude RAG用 高精度プロンプト
XML
あなたは、提供された資料のみを根拠に回答する専門アシスタントです。 以下の手順で回答してください。
質問:{{ユーザーの質問}}
回答の根拠(ソース)を明示させる命令文
「答えのあとに、どの資料のどの部分を参考にしたか必ず書いてください」と一行付け加えましょう。これだけで、ユーザーはAIの回答を盲信せずに済みます。
資料にIDを振っておき、「[Source: Doc-001]」のように出力させるルールを作ると、さらに管理がしやすくなります。
「分からないときは答えない」と制約をつける理由
AIはサービス精神が旺盛すぎて、答えがないときでも無理やり何か言おうとしてしまいます。これを防ぐために「資料に基づかない推測は一切禁止します」と強めに制約をかけましょう。
「知らない」と言えるAIこそ、ビジネスの現場では最も信頼される存在になります。
外部データ連携をスムーズに進めるための工夫
最後に、システムを快適に使い続けるためのちょっとした工夫を紹介します。レスポンスの速さやコストは、運用の満足度に直結する大事なポイントです。
回答速度を上げるためのキャッシュ活用
同じような質問が何度も来る場合は、Claudeの「プロンプトキャッシュ」機能を使いましょう。一度読み込ませた大量の資料をメモリに一時保存しておくことで、2回目以降の回答スピードが爆速になります。
毎回資料を読み直す手間が省けるため、待ち時間のストレスが大幅に減ります。
トークン消費を抑えてコストを削る方法
資料を全部渡すのではなく、検索で絞り込んだ「本当に必要な部分」だけを渡すように調整しましょう。Claudeに渡す文字数が減れば、それだけAPIの利用料金も安く抑えられます。
精度の高い検索エンジンを組み合わせることは、節約にも繋がるのです。
最新のオープン規格「MCP」で連携を楽にする
Anthropicが発表した「MCP(Model Context Protocol)」という仕組みを使えば、ローカルにあるファイルや外部ツールとの接続が今まで以上に簡単になります。
これまでエンジニアが苦労して繋いでいた部分を共通化できるため、今後のアップデートでさらに活用の幅が広がるはずです。
まとめ:Claude RAGで自分だけの専門AIを作ろう
Claudeと外部データを連携させるRAGは、AIを「ただの話し相手」から「頼れる実務パートナー」へと進化させる最高の手段です。仕組みはシンプルですが、データの整え方や検索の工夫一つで、その精度はどこまでも高めることができます。
- RAGはAIに「参考書」を持たせて回答させる仕組み
- Claudeは大量の資料を一度に読み解く力が非常に高い
- 精度アップの鍵は、読み込ませる前のデータの「お掃除」にある
- Amazon Bedrockなどを使えば、手軽に本格的な環境が作れる
- XMLタグを使ったプロンプトで、情報の混同を防ぐのがコツ
- 分からないときは「知らない」と言わせる設定が信頼を生む
まずは手元にある数枚のPDFから始めてみてください。Claudeがあなたの専門知識を完璧に理解して受け答えする様子を見れば、きっとその可能性に驚くはずです。








